
業務にて、Hadoopの導入をしたのですが、インターネット上で調べてみると、残念ながら数年前の古い記事ばかりでした。そのため、今回私たちが手がけた Hadoop 3.3 のインストール手順についてまとめてみました。
分散処理技術 Hadoopとは
インストール手順の前に、まずはHadoopについて簡単におさらいをしましょう。
Hadoopとは、大規模データの分散処理を支えるJavaソフトウェアフレームワークです。
このフレームワークは、二つの機能を組み合わされています。
・データを分散させるための「HDFS」
・分散させたデータを効率よく処理するための「MapReduce」
Hadoopの主な特徴は以下となります。
・データ入力時のスキーマ定義が不要
・非構造化データ(ログ、画像等の構造定義をもたないデータ)を扱える
・サーバーを後から追加することができ、そのため、容量および処理性能を向上させることが可能
・サーバーの故障や通信障害をシステムが検出し、その時点でリカバリ処理が可能
しかしながら、Hadoopにも欠点があります。
同じ処理を複数回実行する場合や、同じデータに何度もアクセスする場合、その都度ストレージへアクセスを行います。そのため、インメモリ型のストレージでなければ、実行処理が遅くなるため、リアルタイムの処理には向きません。
そのため、一般的には、頻繁にアクセスが発生しないような大規模のデータの蓄積と処理に使用されることが多いのが現状です。
Hadoop 3.3 のインストール方法
導入環境
- ・Centos7 (64bit)
- ・rpm 4.14.2
- ・JDK 14.0.1
- ・Hadoop 3.3.0
JDK(Java SE Development Kit)のインストール
「Hadoopのインストールは?」と思われた方もいるかもしれません。
前の項でHadoopはJavaソフトウェアフレームワークと書きましたが、HadoopはJavaで作られています。
そのため、Hadoopを操作するにはJavaが必要となります。
公式HPにおいて「Apache Hadoopコミュニティはビルド/テスト/リリース環境にOpenJDKを使用している」との記載があります。前準備として、まずは、OpenJDKをインストールします。
以下の公式サイトよりダウンロードしてください。
注意として、インストールする場合、事前にJavaのバージョンを確認する必要があります。
公式HPによるとHadoop3.3以降はJava 8およびJava 11をサポートしていますので、今回はこのバージョンをインストールします。
OpenJDKをインストール
OpenJDKはyumでインストールします。
> yum install java-1.8.0-openjdk
> yum install java-1.8.0-openjdk-devel
インストール後はjavaコマンドを入力し、バージョンを表示するか確認をしてください。表示されれば、インストールは完了です。これでjavaを動かす環境ができました。
> java -version
インストール先の確認
Hadoopをインストールする場合、OpenJDKの保存先を設定する必要があります。そのため、そのパスを確認をしておきましょう!
今回の環境では【/usr/lib/jvm/java-1.8.0-openjdk】でした!
インストールが完了したら、コマンドプロンプトから確認を行います。
Hadoop 3.3 のインストール
ここから、Hadoop 3.3 のインストールを行います。
Hadoop 3.3 インストール用のファイルをダウンロード
まずは Apache Hadoopプロジェクトの公式サイトからHadoopのソフトウェアをダウンロードします。
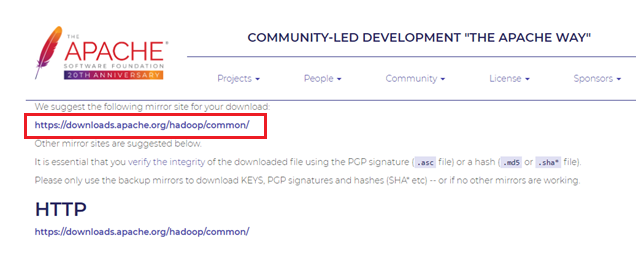
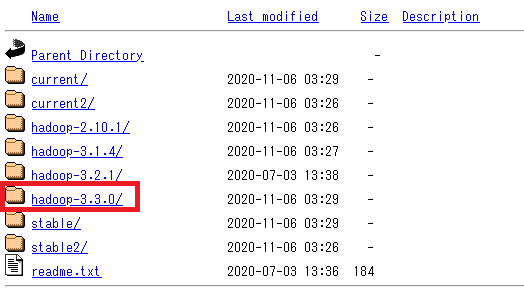
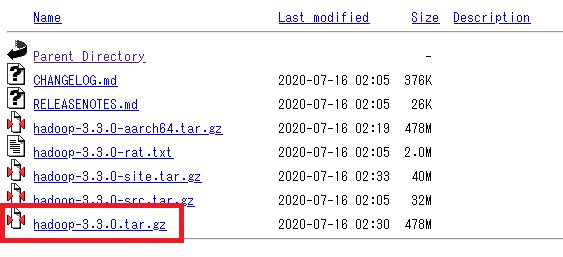
ダウンロードするファイルは【hadoop-3.3.0.tar.gz】です。
以下のコマンドでファイルをダウンロードします。
> wget https://ftp.kddi-research.jp/infosystems/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
ダウンロードしたファイルの解凍
JDKをインストールしたときと同様に、ターミナルからスーパーユーザーでログインし、ファイルを操作します。
操作するのは【hadoop-3.3.0.tar.gz】となります。
Hadoopのインストール用ファイルは圧縮されているので解凍します。
> tar zxvf hadoop-3.3.0.tar.gz
解凍をすると、圧縮ファイルと同じ場所に【hadoop-3.3.0】というディレクトリが作成されます。このディレクトリは、自身で扱いやすい場所へ移動させておきます。
※今回は【/usr/local】に移動しました。
PATHの設定
ここで、PATHを設定します。
Hadoopを使用するには、HadoopとJavaの2種類のPATHを設定する必要があります。
設定のため、root配下の【.bashrc】を編集します。
> vi ~/.bashrc
以下の情報を【.bashrc】の最終行に追加してください。
JAVA_HOME=/usr/java/jdk-14.0.1
HADOOP_INSTALL=/usr/local/hadoop-3.3.0
PATH=$HADOOP_INSTALL/bin:$JAVA_HOME/bin:$PATH
変更を保存したら、コマンドを実行して変更を反映させます。
> source ~/.bashrc
インストールの確認
ここでは、Hadoopがインストールされているかをコマンドを実行して確認します。
> hadoop version
バージョンが表示されたなら、インストール完了です!
これで、Hadoopのインストールは完了です。
インストールされた時点、Hadoopは自動的にスタンドアロンモードとなります。そのため、ローカルファイルの操作が可能となります。
まとめ
今回はHadoop 3.3のインストール手順を説明してみましたが、いかがでしたでしょうか?
この記事では、Hadoopのバージョン 3.3.0を使っていますが、2022年10月時点の最新バージョンであるHadoop 3.3.4でも、インストール方法は同じとなります。
データレイクのキーテクノロジーであるHadooop。ぜひともデータ活用の基盤としてご活用いただければ幸いです。
本記事は、弊社先端技術開発グループが運営している「note」内の「AIグループ@グランバレイ」の記事を一部修正を加え転載しております。
https://note.com/gvaiblog/n/nd4df9ec910c6
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 予測分析で意思決定を加速化。自動機械学習「Qlik AutoML」とは
予測分析で意思決定を加速化。自動機械学習「Qlik AutoML」とは
-
 AI・機械学習・アナリティクスで成功するための4つの戦略
AI・機械学習・アナリティクスで成功するための4つの戦略
-
 データプレパレーションプロセスとETLにAIが活躍できる7分野
データプレパレーションプロセスとETLにAIが活躍できる7分野
-
 データの可視化に必須のチャート13選
データの可視化に必須のチャート13選
-
 SAP 生成AIアシスタント/コパイロット「Joule(ジュール)」
SAP 生成AIアシスタント/コパイロット「Joule(ジュール)」
月別記事一覧
- 2025年3月 (1)
- 2025年2月 (1)
- 2025年1月 (1)
- 2024年12月 (1)
- 2024年10月 (1)
- 2024年8月 (1)
- 2024年7月 (2)
- 2024年6月 (1)
- 2024年4月 (1)
- 2024年2月 (1)
- 2024年1月 (1)
- 2023年9月 (1)