
企業がデータ分析と意思決定に取り組むにあたり、人工知能(AI)は変革をもたらします。今、製品やサービスに分析機能を追加するのであれば、AI、機械学習、予測モデリングを織り込む必要に迫られています。
生成AI(ジェネレーティブAI)の急速な発展に伴い、自社のプロダクト担当者は、多くの価値を引き出し、ユーザーを引き付け、競争優位性を高めるられるため、自社のロードマップを再検討し、それらの導入を推し進めています。実際、最近のマッキンゼーの調査によると、回答者の40%が、生成AIの進歩により、AIへの投資を増やすと回答しています。
このように、AI導入が進む中、全てが成功するとは言えません。成功の鍵は、AIの取り組みがユーザーに真の価値を確実に提供することと言えます。
生成AIは、ユーザーがデータに関わる新しい方法を提供し、分析をより身近なものにし、データに関する説明をほぼ瞬時に提供することが可能となります。
例えば、生成AI技術をアナリティクスに正しく適用することで、企業はより正確な予測を立て、迅速に行動することができるようになります。また、手作業による分析では発見できなかったり、時間がかかりすぎたりするような、大規模で複雑なデータセット内の隠れたパターンや相関関係、関係性を迅速に発見することも可能になるでしょう。
アナリティクスを実用的なものにする予測モデリングの活用
アナリティクスをAIで強化しようとお考えなら、機械学習は予測モデリングから始まります。予測モデリングは、機械学習の中でも最も成熟しており利用しやすい機能の1つであり、利用者がデータから価値を得るための最も実用的な方法の1つとなります。
簡単に始められる手法:回帰分析
最も簡単に始められるのは回帰分析となります。例えば、売上予測分析を提供したい場合、回帰分析を使って、過去の売上データ、顧客行動、市場動向、その他の関連要因に基づいて将来の売上を予測することができます。利用者はそれを使い、販売目標を設定し、販売リソースをより適切に配分することが可能となります。
もう一つの一般的な例は、需要予測です。この場合、回帰分析によって、価格、マーケティング、競合他社の活動、過去の販売データに基づいて、製品やサービスの需要を予測することができます。これは、ユーザーが生産と在庫を最適化し、需要に見合った適切な量の製品を倉庫に保管するのに役立ちます。
Sisenseは、アプリケーションに回帰分析を容易に追加できます。データセット内の連続変数の単変量および多変量予測を自動的に作成し、AutoMLを使用した高度な予測をするために、ビジネスユーザー向けのポイント・アンド・クリック、ノーコードのワークフローを提供します。
また、回帰分析の成功の鍵は、適切なデータセットに適切なモデルを使用することです。そのため、Sisenseでは、Auto Arima、Prophet、Random Forest、Holt-Winters、Boost Spline、Ranger (Random Forest)、XGBoost、CatBoost、Elastic Netを提供し、豊富なモデルの中からベストな選択をすることができます。
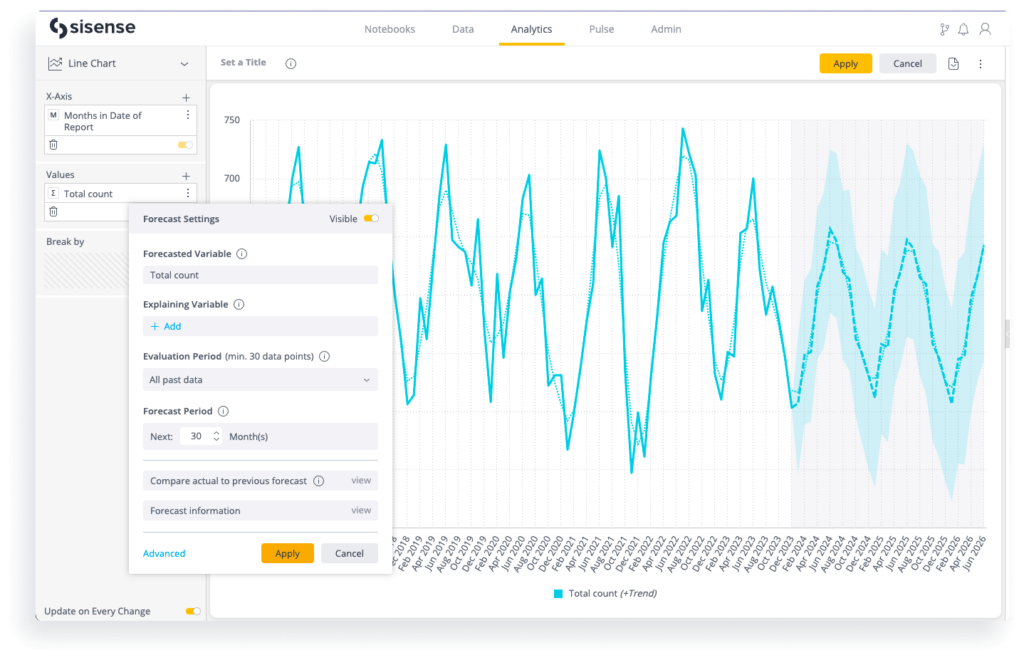
その他の予測戦略を取り込む: 時系列分析と決定木分析
AI、機械学習、予測モデリングに慣れてきたら、時系列分析から決定木分析まで、回帰、分類、その他の機械学習手法を使った予測戦略を取り入れることも検討します。
例えば、分類予測モデリングは、入力データの特徴に基づき、新しいオブザベーションを事前に定義されたクラスやカテゴリーに分類するモデルをトレーニングすることで機能します。この分析はヘルスケア、金融、マーケティングなど様々な分野で利用できます。
時系列分析は、時間とともに変化するデータの分析と予測に重点を置くため、売上動向から人口の健康状態の変化まで、将来の値を予測するためにパターン、トレンド、季節変動を可視化することが可能となります。
もう一つの予測モデリング手法として「決定木分析」があります。決定木分析は、分類木と回帰木を組み合わせたもので、ツリー(樹形図)によってデータを分析する手法です。機械学習や統計、マーケティングや意思決定などさまざまな分野で用いられ、顧客がサブスクリプションベースのサービスを解約するか、継続するかを予測するために使用することが可能です。
また、決定木分析は、契約タイプ、月額料金、インターネットサービスタイプ、支払い方法、契約期間などの顧客データに基づいている。基本的には、特定の基準に基づいて顧客を分類する一連の分岐と決定ポイントを経て、最終的に解約リスクがあるかどうかの判断も可能となります。
Sisenseでは、複雑な機械学習ベースのモデルを簡単に取り入れ、利用者が容易に利用できるようにすることに開発しています。Sisenseの計算式でRを利用したり、Sisense のForecastやTrend Analysisなどすぐに使える機能を使用することで、様々な予測モデリング技術をアナリティクスに取り入れることができます。後者では、データサイエンティストに頼ることなく、利用者自身が容易に異常や傾向を特定することができます。
クラスタリング・アルゴリズム技術は、より多くの洞察を提供する
アナリティクスにおける機械学習テクニックは、一般的にクラスタリング・アルゴリズムを採用しています。その理由として、クラスタリング・アルゴリズムによって、データセット内のパターン、構造、関係を特定することができるからです。また、特定の基準やその他の類似性に基づいて、類似したデータ・ポイントをグループ化も可能となります。
例えば、あなたがマーケティング向けのアプリケーションやサービスを提供していると仮定します。クラスタリング・アルゴリズムを利用することで、顧客を性別・年齢・居住地域・職業・家族構成・年収・学歴などの属性や、行動、購買パターンに基づいたセグメントに分けることができます。これらセグメンテーションをダッシュボードで可視化することで、あなたは異なる市場セグメントを理解することができ、その結果、マーケティング戦略の見直しや最適化、製品開発やターゲットオーディエンス拡大のための新たな施策策定に役立てることができるでしょう。
また他の利用例として、金融サービスから製造業等、あらゆる分野で重要な「異常検知」にクラスタリング・アルゴリズムの活用です。クラスタリング・アルゴリズムは、データセットの異常パターンや異常値を検出することができます。これにより、不正行為の検出、製造上の欠陥の特定、ビジネスのリスク等の発見などができるようになり、これらを軽減するため、マネージメントは事前対策や予防を講じることを可能にします。
では、クラスタリング・アルゴリズムはどのような手法が使われているでしょうか。
最も一般的なものはK-means法です。データサイエンティストは「R」を使い解析をしています。「R」とは統計モデリング、機械学習、時系列分析などの業界標準のオープンソース統計解析言語およびその開発実行環境です。
Sisense では、R を組み合わせることでクラスタリングアルゴリズムを簡単に統計解析をすることができます。Sisenseフォーミュラエディターで直接R言語を書き、SisenseフィールドをRの式にパラメータとして送ることで結果を得られます。
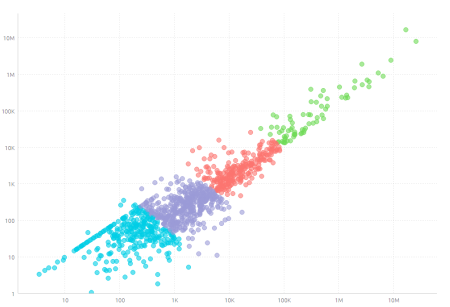
例えば、以下の Sisense の Total Cost と Total Revenue フィールドは、K-means 関数によってデータをクラスタリングするために使用されています。結果はK-meansの設定に基づいてデータをクラスタ化し、この場合は4クラスタとなる。
RINT(TRUE, “m
kmeans(m,4)$cluster” ,[Total Cost],[Total Revenue])
Total CostとTotal Revenueを可視化する際、分析者はクラスタリング結果を適用することで、母集団に対し4つの主要セグメントを明確に識別し、さらなる分析を行うことができるようになります。
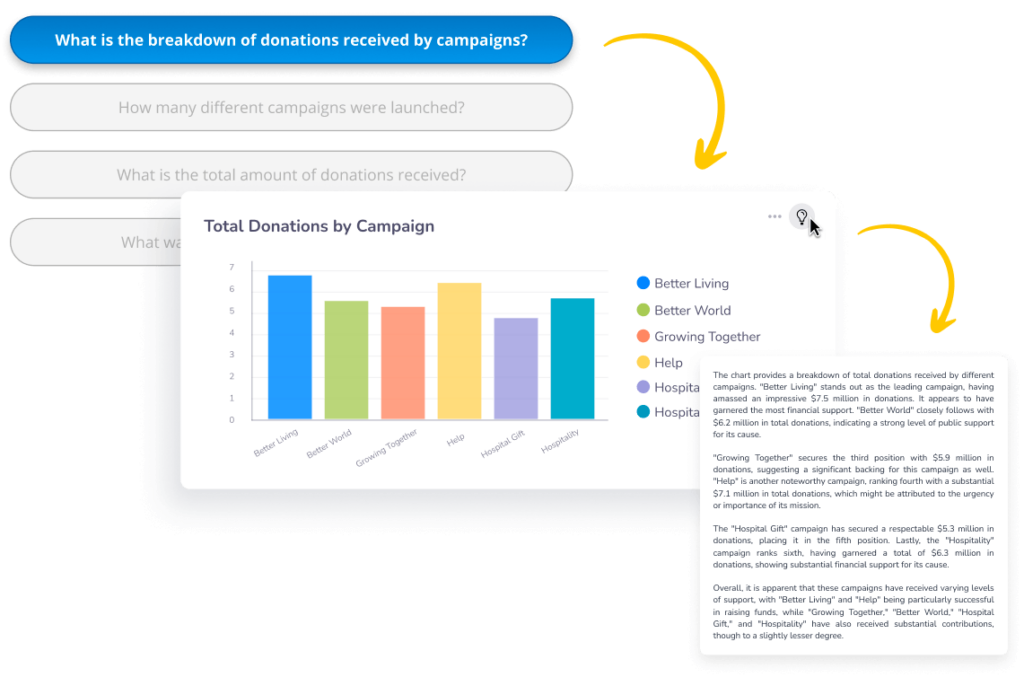
生成AIから始める-強化されたLLMを利用する
生成AIはAIの異なる一分野であり、一般的にディープラーニング手法に基づいています。これらのモデルは大規模なデータセットで学習され、データの基礎となるパターンや構造を学びます。一度学習されると、文字などの入力(プロンプト)に対して、テキストから画像や動画まで、プロンプトに似た特徴を持つ結果(コンテンツ)を生成します。
多くの人はChatGPTや様々なコパイロットを通じて大規模言語モデル(LLM)に慣れ親しんでいます。特にLLMは、アナリティクスに適用された場合、別の重要な機会を提供します。
ロバスト・セマンティックセグメンテーションで補強されたLLMは、自然言語クエリ(NLQ)システムのパワーとして使用することができます。LLMは質問の文脈を理解しながら、データウェアハウスから結果を取得することができます。また、生成AIは結果セットを説明するのに役立つストーリーの要約も提供可能です。
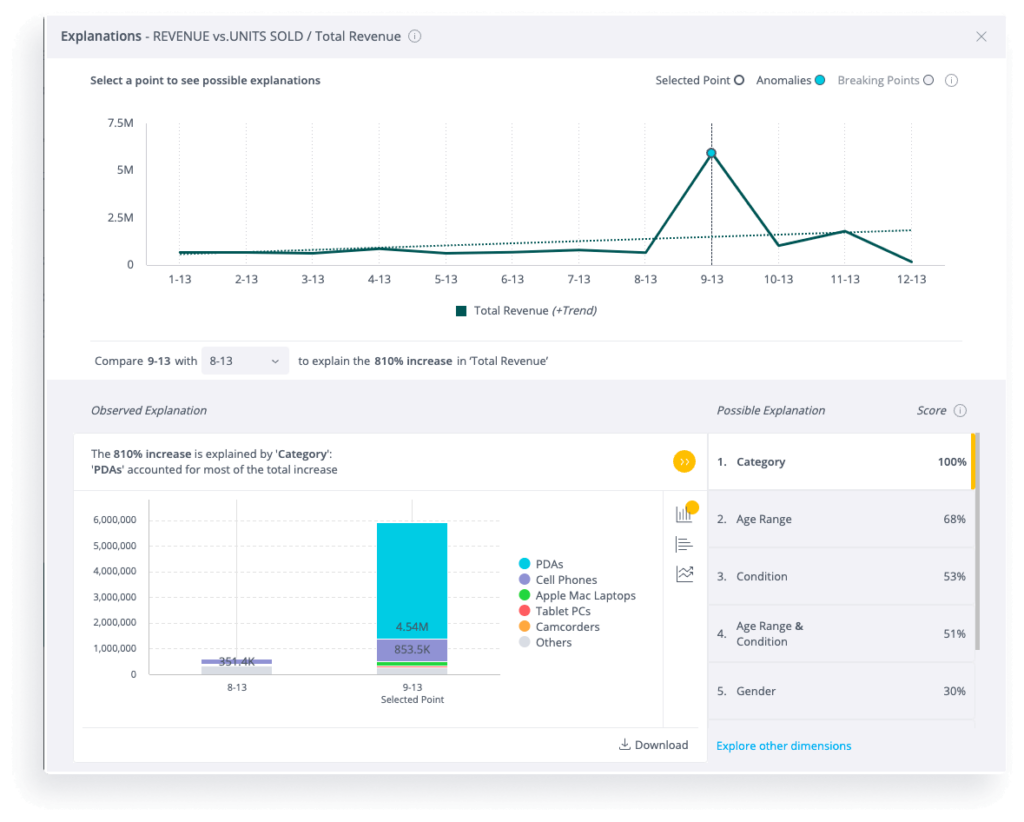
説明可能なAIを活用しアナリティクスの信頼性を高める
説明可能なAI(Explainable AI)は、AIの振る舞いをあらゆる観点から理解し、信頼できるようにすることを目的とする技術の総称で、どのようなAI、機械学習、生成機能を使用する場合でも非常に重要な技術となります。
異なるAIによるアプローチがデータベースや生データ上で異なる方法で直接機能する場合、AIが導き出した答えについて、「なぜその答えを出したのか」が説明するのが困難になります。
説明可能なAIとは、利用者がデータに関する説明を簡単に得られるようにAIを利用することも意味します。例えば、SisenseのExplanations機能は、ユーザーが一連のデータポイントを選択し、機械学習を使ってデータの変化の背後にある最も可能性の高いキードライバーを特定することを可能にする。これは、おそらく最もビジネス・アクセスしやすい意味での説明可能なAIである。Sisense Explanations機能は、様々な要因の可能性をスキャンし、選択された一連のデータの背後にある最も重要なドライバーであった上位のフィールド(またはフィールドの組み合わせ)を提示します。数字の背後にある「なぜ」を知るための説明可能性を提供します。
今回、Sisenseを例にアナリティクスとAIを組み合わせるための4つの戦略をまとめてみました。他社のアナリティクス製品でも、RやAIを組み合わせて利用することで同様の機能をもたらすことができるでしょう。この機会に是非ともAI、機械学習、アナリティクスの活用について今一度振り返ってみることをお勧めします。
この投稿に記載されているすべてのデータは情報提供のみを目的としており、正確ではありません。前もってご了承ください。
本記事は、Sisense社の許諾のもと弊社独自で記事化しております。
https://www.sisense.com/blog/4-strategies-for-success-with-ai-machine-learning-and-analytics/
※ SisenseおよびSisense Hunchは、Sisense Inc の商標または登録商標です。
※ その他の会社名、製品名は各社の登録商標または商標です。
※ 記事の内容は記事公開時点での情報です。閲覧頂いた時点では異なる可能性がございます。
キーワード
注目の記事一覧
-
 予測分析で意思決定を加速化。自動機械学習「Qlik AutoML」とは
予測分析で意思決定を加速化。自動機械学習「Qlik AutoML」とは
-
 AI・機械学習・アナリティクスで成功するための4つの戦略
AI・機械学習・アナリティクスで成功するための4つの戦略
-
 データプレパレーションプロセスとETLにAIが活躍できる7分野
データプレパレーションプロセスとETLにAIが活躍できる7分野
-
 データの可視化に必須のチャート13選
データの可視化に必須のチャート13選
-
 SAP 生成AIアシスタント/コパイロット「Joule(ジュール)」
SAP 生成AIアシスタント/コパイロット「Joule(ジュール)」
月別記事一覧
- 2025年3月 (1)
- 2025年2月 (1)
- 2025年1月 (1)
- 2024年12月 (1)
- 2024年10月 (1)
- 2024年8月 (1)
- 2024年7月 (2)
- 2024年6月 (1)
- 2024年4月 (1)
- 2024年2月 (1)
- 2024年1月 (1)
- 2023年9月 (1)